

Which districts are best at teaching students to read?
And how to adjust for demographic factors
Improving 3rd grade reading scores is one of the three goals set for the superintendent by the board. The district is hoping to have 70% of 3rd graders meeting ELA standards by 2027. When this goal was first announced, I described it as “Wayne’s Mission Impossible” so I haven’t been at all surprised by the district’s lack of progress.
A recent article in The74 (a nonprofit news site focused on education - the name refers to America’s 74 million children) attempted to answer the question of “which school districts do the best job of teaching kids to read?” The text of the article is well worth reading and I’ll have more to say about it later. But the underlying numerical analysis was slapdash. It’s possible to produce a much better analysis with not much work, as I hope to demonstrate.
Here’s the California chart from the article with San Francisco highlighted.
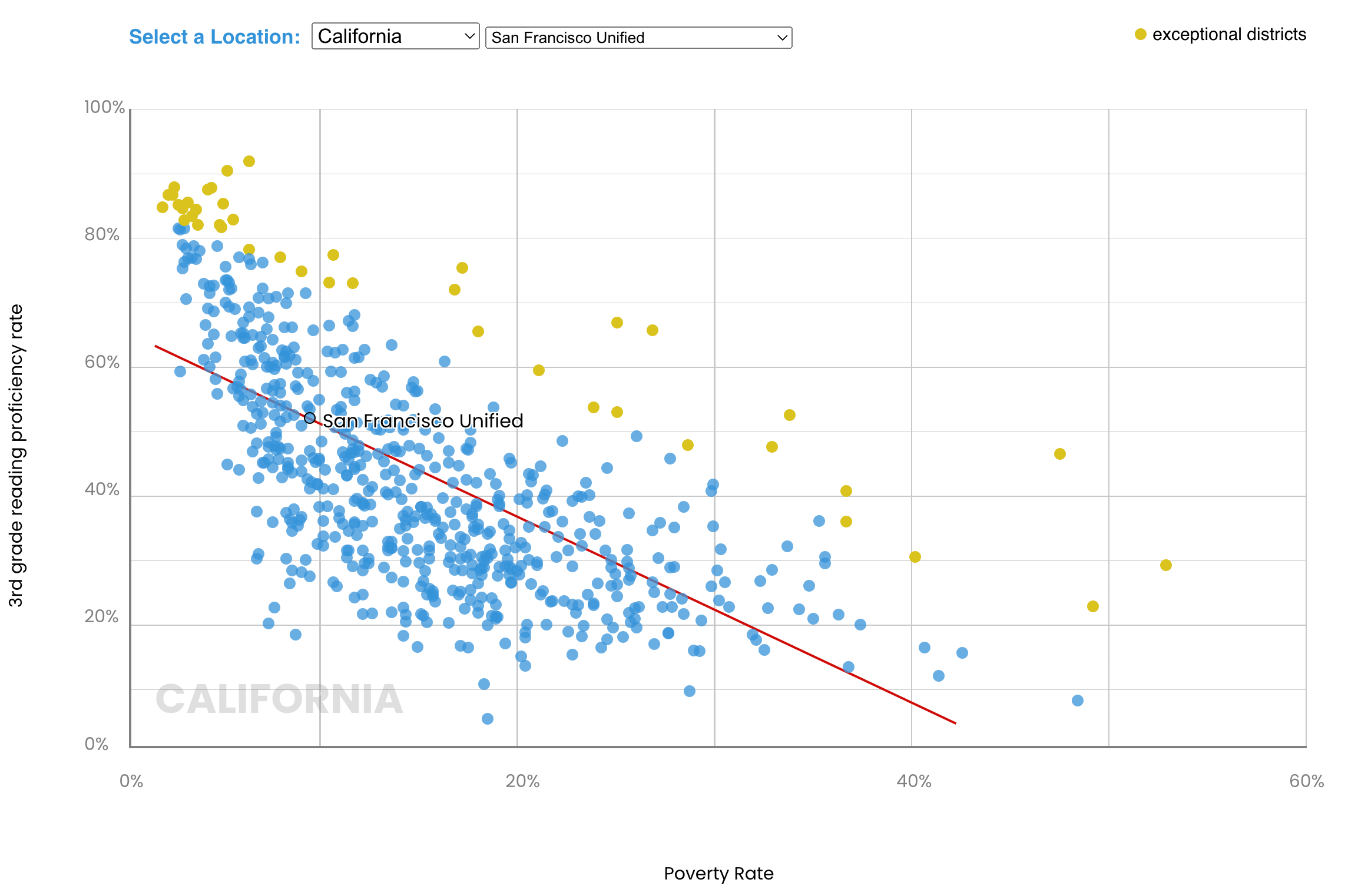
Here’s my version of the same chart. It’s based on exactly the same data but the chart is not absolutely identical because there are multiple districts in California that share names (e.g. Mountain View Elementary) and the original chart mixed them up.
What the author did was compare the poverty rate1 in each district with the percentage of 3rd grade students who were proficient in reading (i.e. who met or exceeded standards on the SBAC ELA test). The red line in the chart is the line that best fits the data assuming that there is a linear relationship between poverty and reading proficiency rates. The line represents the predicted proficiency rate for each poverty rate. Districts above the red line do better than expected, given their poverty rates. The “exceptional” districts are the 5% who most outperform their predicted proficiency level. San Francisco lies right on the line, meaning that it does exactly as well as expected, no more, no less.
The R-squared of 0.466 is a measure of how good a fit the line is to the data. It means that 46.6% of all the observed variation in proficiency rates can be explained by the districts’ poverty rates. The author’s assumption is that the remaining 53.4% is due to the efforts of the districts. As we shall see, other demographic factors explain far more of the variation than 46.6% and this has the effect of completely changing which districts are identified as exceptional.
Improvement #1: Free Meal eligibility rate
Let’s start by looking back at the chart above. Notice that practically all of the districts with poverty rates below 5% or above 30% surpass their predicted proficiency rates. If there really were a linear relationship between poverty rates and proficiency, some of those districts should fall below their expected proficiency rates. That they don’t indicates that something about the model is wrong.
Part of the problem is that the poverty rate is just not very precise. The poverty rate is calculated by the census bureau by mashing together “multiyear American Community Survey (ACS 2006-2010) estimates, aggregated tax data and…model-based estimates of poverty for all counties”. According to the bureau, the estimated poverty rate may differ from the true poverty rate by as much as 25% for the largest districts (and by much much more for the smallest districts). Furthermore, it is based on an estimate of the number of school-age children living in each district, regardless of whether or not they attend the district’s schools. This is going to give an inaccurate number for districts like San Francisco where 30% of students attend private schools.
A more powerful measure of poverty is the percentage of students eligible for free meals, as reported by the California Department of Education (CDE). By “more powerful”, I mean that it explains more of the variation in reading proficiency rates. Some of this extra power may be because on an actual count of students in each district rather than a statistical estimate.
Children are eligible for free meals in California if their family income falls below defined thresholds or they are receiving CalFresh or CalWORKs benefits. The thresholds are higher than the federal poverty threshold so more students are eligible for free meals than are in federal poverty. However, it’s not a predictable relationship. Los Angeles Unified and Hesperia Unified (San Bernardino) both have poverty rates of 21% but their free meal eligibility rates are 81% and 56% respectively. San Francisco and Santa Monica-Malibu both have poverty rates of 9% but the free meal eligibility rates are 48% and 24% respectively.
Just switching from the poverty rate to the free meal eligibility rate increases the R-squared from 0.466 to 0.676.
In California, school districts get extra funding from the state depending on their Unduplicated Pupil Count (UPC), which counts the number of students who are eligible for free or reduced price meals or who are English Learners. I assumed that we would be able to explain even more of the variation in districts’ reading proficiency rates if we also took into account the share of students who were English learners or who were eligible for reduced-price meals. I was wrong. These don’t improve the R-squared even a tiny bit.
Improvement #2: Socioeconomic Disadvantage
So far, we’ve been using the free meal eligibility rate of the district to predict the reading proficiency of 3rd graders. It would be cleaner if we could use the free meal eligibility rate of 3rd graders but that data is not available. What is available is the rate of socio-economic disadvantage, which is a broader category. In addition to those eligible for free and reduced-price meals, it includes those who are homeless, or in foster care, or whose parents did not graduate high school (but not English learners).
If we predict 3rd grade reading proficiency using 3rd grade economic disadvantage, we get an R-squared of 0.695
If you mouseover the districts that appear to be exceptionally good (or exceptionally bad), you’ll notice that many of them have very few students. It’s hard to know whether these districts are truly exceptionally good or whether they’ve just been the beneficiaries of statistical noise2.
A proper research paper would conduct statistical tests to identify districts whose overperformance can’t be explained by luck. This is not a proper research paper. To illustrate how much randomness affects the results, look what happens when we simply exclude the smallest districts. This chart shows exactly the same data as the previous one but excludes districts with fewer than 300 students which were included in the previous chart. Just by getting rid of the outliers, the R-squared jumps from 0.695 to 0.767.
Using this measure, San Francisco now scores a little bit above its predicted level but still far below where it needs to be if it is to achieve its long-term goal. To achieve that goal, it will need to be above the 99th percentile of all districts. The districts in that percentile today are all much much smaller than San Francisco.
Improvement #3: Parental Education
Adding race/ethnicity to socioeconomic disadvantage improves the prediction a bit. The R-squared rises from 0.767 to 0.808. Effectively, knowing whether the disadvantaged students are Asian or Latino improves the quality of the reading proficiency estimate because Asian students are more likely to be proficient.
But there is one variable that performs even better: the percentage of students whose parents graduated college. This one variable, by itself, accounts for 84.2% of all the observed variation3 in reading proficiency between districts. Everything else that we obsess about - school funding, curriculum, teacher pay, quality of instruction, class sizes - just affects the remaining 15.8%.
In this chart, San Francisco lies a bit below the best-fit line i.e. it does slightly worse than would be predicted given the percentage of children whose parents who graduated college. I wouldn’t sweat over this. The main point is that the 2027 goal still looks unattainable.
Notes for statistics nerds
Districts that have high parental education levels are also filled with White and Asian students and have low rates of socioeconomic disadvantage. Since there is such high correlation between these variables, a multiple regression using two or more of them doesn’t improve the R-squared by much. I experimented with other variables like the percentage of English learners or the percentage of students with disabilities but these were not significant. The best I could come up with in my p-hacking adventures was an R-squared of 0.865, which I achieved with three variables, each of which was significant at a 99.9% confidence level
the share of students whose parents graduated a four-year college.
the share of students whose parents are non-disadvantaged and Asian, White, or of Two or more races
whether the district is in Los Angeles or Orange counties.
I can’t come up with a plausible reason why the last variable should be significant but it is a fact that districts in those counties do better than would be expected based solely on the other factors. Given the relatively small gain (0.842 to 0.865) obtained by adding the two extra independent variables, I opted to stick with the simpler model that uses just one independent variable.
How to get exceptional results
Having spent this entire post dissing the analysis in the article from The74, the reason I still found it worth reading is that it introduced me to districts like Steubenville City in Ohio. Here is the article’s Ohio chart which shows just how exceptional Steubenville is.
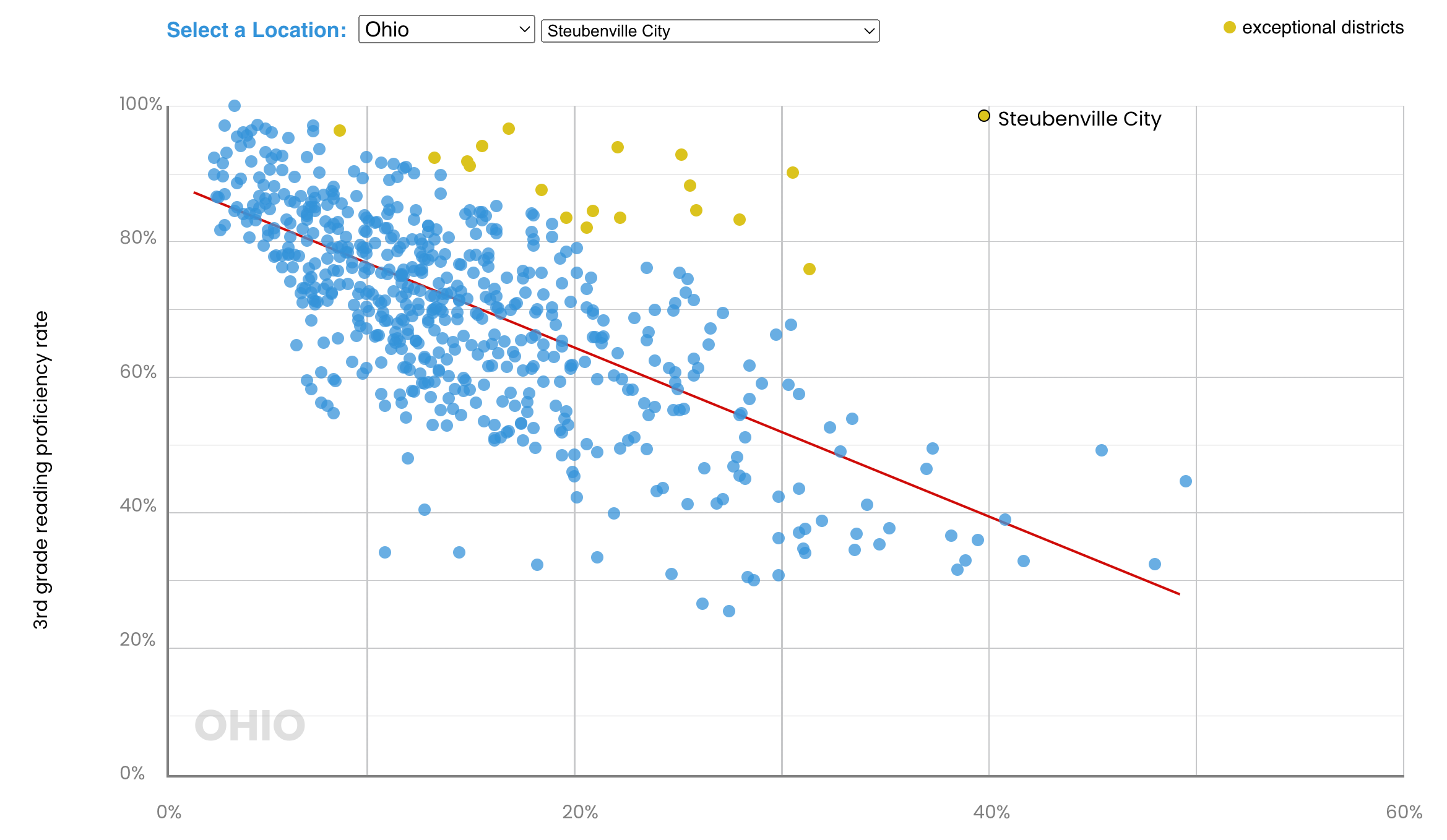
My first thought upon seeing this4 was to suspect either fraud or statistical fluke but Steubenville is not small (it is 75% of San Francisco’s size) and although Steubenville is small, at just over 200 students per grade, (corrected: October 3) it has been getting results like this for years. It has consequently been the subject of many studies, articles, and podcasts. The article links to a few and I took away three lessons from them
Steubenville picked a reading curriculum that is heavily phonics-based and has had a top-to-bottom commitment over many years to implementing that curriculum faithfully, including constant monitoring of students’ progress.
Other districts are loathe to copy Steubenville’s example because the curriculum is very prescriptive. It specifies exactly what teachers are supposed to do every day. This arouses opposition in other districts because it is thought to impinge on individual teachers’ autonomy to plan their lessons as they see fit.
Even at Steubenville, this hard-won outperformance does not carry through to middle and high school grades.
If San Francisco is ever to achieve the goal it has set itself for third-grade reading, it will require a similar top-to-bottom commitment, not simply a change in curriculum.
The poverty rate is the percentage of children whose family income is below the poverty threshold. The threshold varies by year and size of family but, in 2022, the threshold for a family of four with two children under 18 was $29,678.
Every student’s score is an estimate of their true reading proficiency and, like all estimates, is subject to statistical error. Some lucky students will get higher scores than their true abilities would suggest and some unlucky students will get lower scores than their abilities would suggest. If a district is so small that it has only two classes of 3rd graders, it may have a disproportionate number of lucky or unlucky students. In such a small district, one very good or very bad teacher can have an enormous effect on the district’s score. The district’s success may have nothing to do with anything the district is doing (e.g. selecting a curriculum and hiring, training, and monitoring teachers). If this one exceptional teacher leaves, the district’s performance might revert to the average. In larger districts, all the statistical noise tends to average out and we can have more confidence that we’re seeing true over performance rather than just noise.
The line slopes up because I’m using the percentage of children whose parents graduated college as the variable. If I had instead used the percentage of children whose parents didn’t graduate college, it would slope down just like the previous charts.
You can’t compare the proficiency levels in Ohio with those in California because students in the two states take different tests that are not comparable. You can compare Steubenville to other districts in Ohio.
Thanks for writing this, very interesting! I am curious why Steubenville hasn't been studied more closely since 2017 (it appears).
Also, is there more granular testing data within San Francisco? To know whether there are other (positive) outliers between schools within the district that may yield evidence of other factors that can improve performance.
Finally, SFUSD started a new reading curriculum this year (and is piloting a new math curriculum at some schools) so there may messy results in the next few years. For example, teacher difficulties in implementing the new curriculum at first, students adjusting to the new curriculum, reading resource aides being added (or dropped) to schools to assist with the new curriculum, etc.
Great work as always. Someone should hire you to do this. It’s too bad you can’t back out the percentage of kids in private school for chart 3. What percentage of private school kids take the SBAC?